Benchmarking budget storage solutions
Overview of Options
Trade-offs. There isn’t a good or bad solution, there’s only solutions that fit your use case better than others. looks interesting for many uses cases, but if you want a general purpose file system, it’s probably not it.
| ZFS | MooseFS | Ceph | SeaweedFS | |
|---|---|---|---|---|
| Block Size (Min) | 512B | 64KiB | 4KiB | 8B |
| Block Size (Default) | 128KiB | 64KiB | n/a | n/a |
| Block Size (Max) | 1MiB | 64KiB | a | n/a |
| Block Size Property Name | zpool ashift | n/a | min_alloc_size | n/a |
| --- | --- | --- | --- | |
| Chunk Size (Min) | 1MiB | 64KiB | a | |
| Chunk Size (Max) | 1MiB | 64MiB | a | |
| --- | --- | --- | --- |
ZFS
If your storage needs have a growth rate of less than a TB or two per year, ZFS is pretty hard to beat. The main pain with ZFS comes from needing to really think about pool layout and the trade-offs between safety, capacity, and ease of expansion. Pools with raidz vdevs are optimal with identical size drives, otherwise underutilization occurs (all drives in a raidz vdev are treated as being the size of the smallest drive). Once the smaller drives in a zdev are replaced with larger all of the drives space can be used, but depending on the size of the vdev, that could mean upgrading 1 to N-1 drives in the vdev.
DRAID in OpenZFS 2.1 looks interesting, but it’s pretty new and doesn’t seem to be recommended for pools with less than 24 or so drives.
The folks at rsync.net use ZFS and raidz3 and are still “fairly aggressive” about removing drives when they misbehave. The active involved management is one downside of ZFS, as drive failure is best handled with manual intervention to first asses the situation. While ZFS has hot spares and can automatically handle some issues, the feeling I get from folks that manage large pools is that it’s just too risky to let it all happen automatically. While ZFS can do online drive replacement, how well it performs depends a lot on the vdev config (mirror vs raidz, and number of drives). Ceph and MooseFS also do drive replacement, but they can drain a drive (useful if you don’t have a spare drive bay, but never want to lose redundancy) essentially contracting your total space, and then reshuffling data around onces the drive is replaced.
Ceph
Some on reddit hate the idea for running a single Ceph node “cluster”. And considering how I’ve been burned by Ceph through a combination of my own inexperience and x.1.x releases of Ceph not having any forward compatibility guarantee, I’m not ecstatic to be running Ceph again, but it’s a pretty solid foundation used in many organizations. Others, speak much more highly of Ceph, though the various caveats are noted in follow-up replies. While I haven’t seen ZFS destroy itself personally, there are tales of people loosing ZFS pools, so it’s not as though Ceph has some special issues. If your hardware is unreliable, or you just get really unlucky, everything can fail. None of these setups replace proper backups.
MooseFS
MooseFS is an interesting solution and what I’ve been running for my personal storage for about three years.
After being burned by Ceph (while using hardware that was undersized in RAM), I went looking for alternatives. I’d seen MooseFS years before, but hadn’t yet setup a cluster with it. Three years in, mostly happy, but with macFUSE no longer being open source and projects like restic looking to drop fuse support on macOS, FUSE-based solutions don’t look as appealing for long term support and ease of access from my Macs.

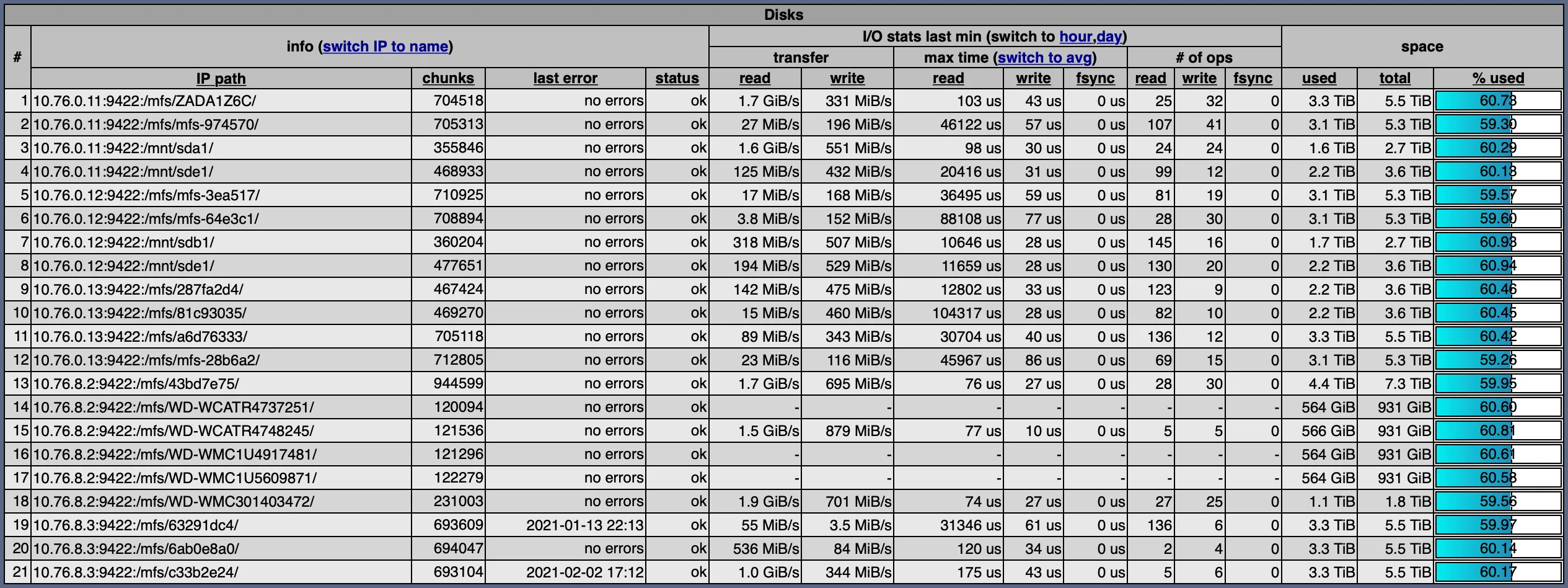
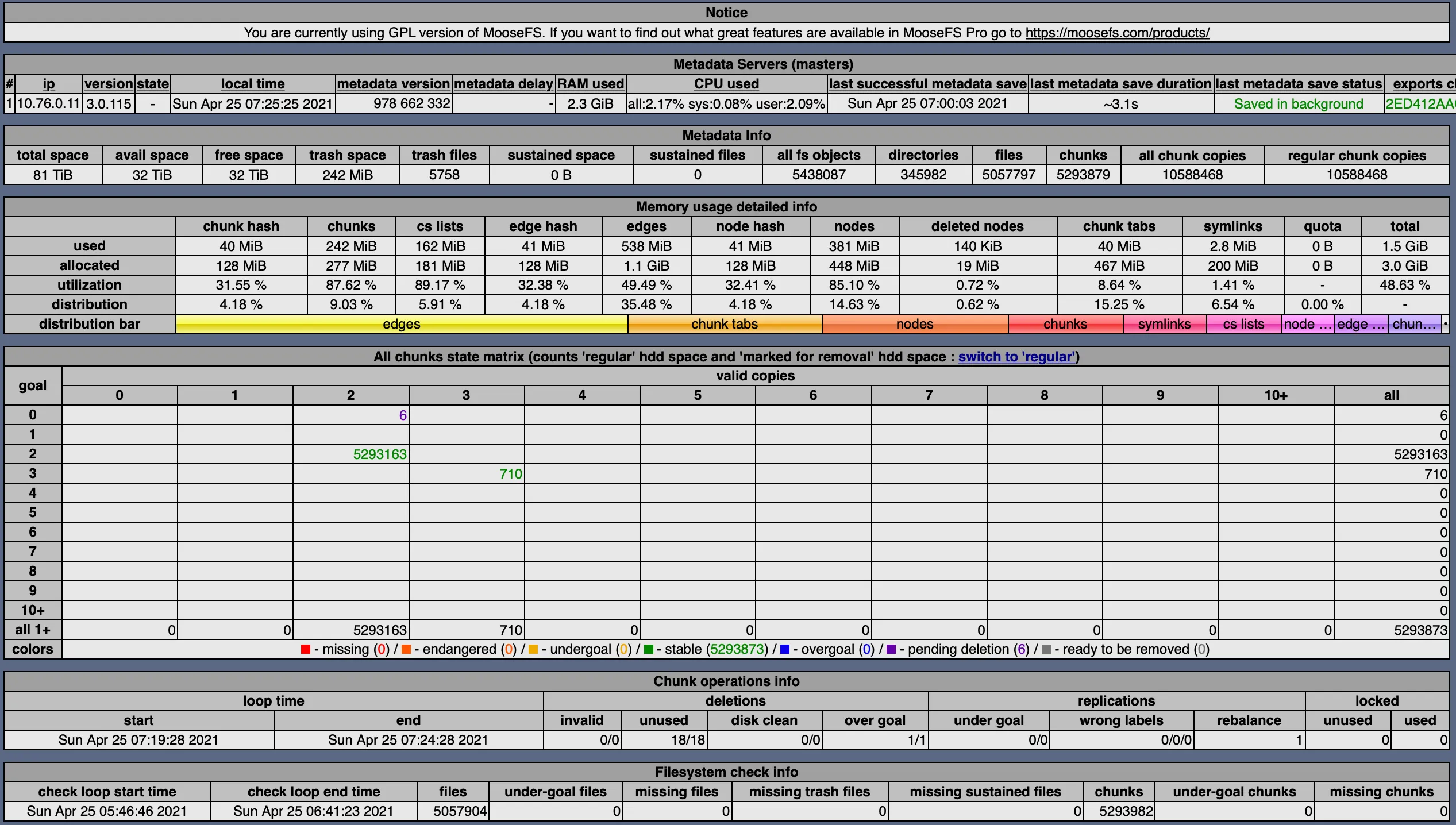

SeaweedFS
I’m really wanting to test SeaweedFS, just haven’t time for it yet.
Test Environment
Hardware
- Dell R610
- Intel Xeon X5675 @ 3.07GHz
- 192 GB RAM
- 6 x 2.5” Intel DC3700 200GB (SSDSC2BA20)
- LSI 9207-8e
- Dell PowerVault MD1220, Split Mode, 2x EMC 1.06 Firmware
- 12 x 2.5” HGST SAS 10K 600GB, HUC109060CSS60, IBM J2EL Firmware
Software
- NixOS
- Linux 5.11.10 #1-NixOS SMP Thu Mar 25 09:13:34 UTC 2021 x86_64 GNU/Linux
- multipath-tools v0.8.3
- System Filesystem: ZFS raidz2
- fio v3.22
- fio-plot
Drive Benchmarks
The 12 x 2.5” HGST SAS 10K 600GB (HUC109060CSS60) drives being used for testing are not great, but okay enough. The comparisons should be a bit more fair while being realistic and balanced across configurations using 12 identical drives vs the random 12-24 2-8TB drives that I’ll be using for the final setup.
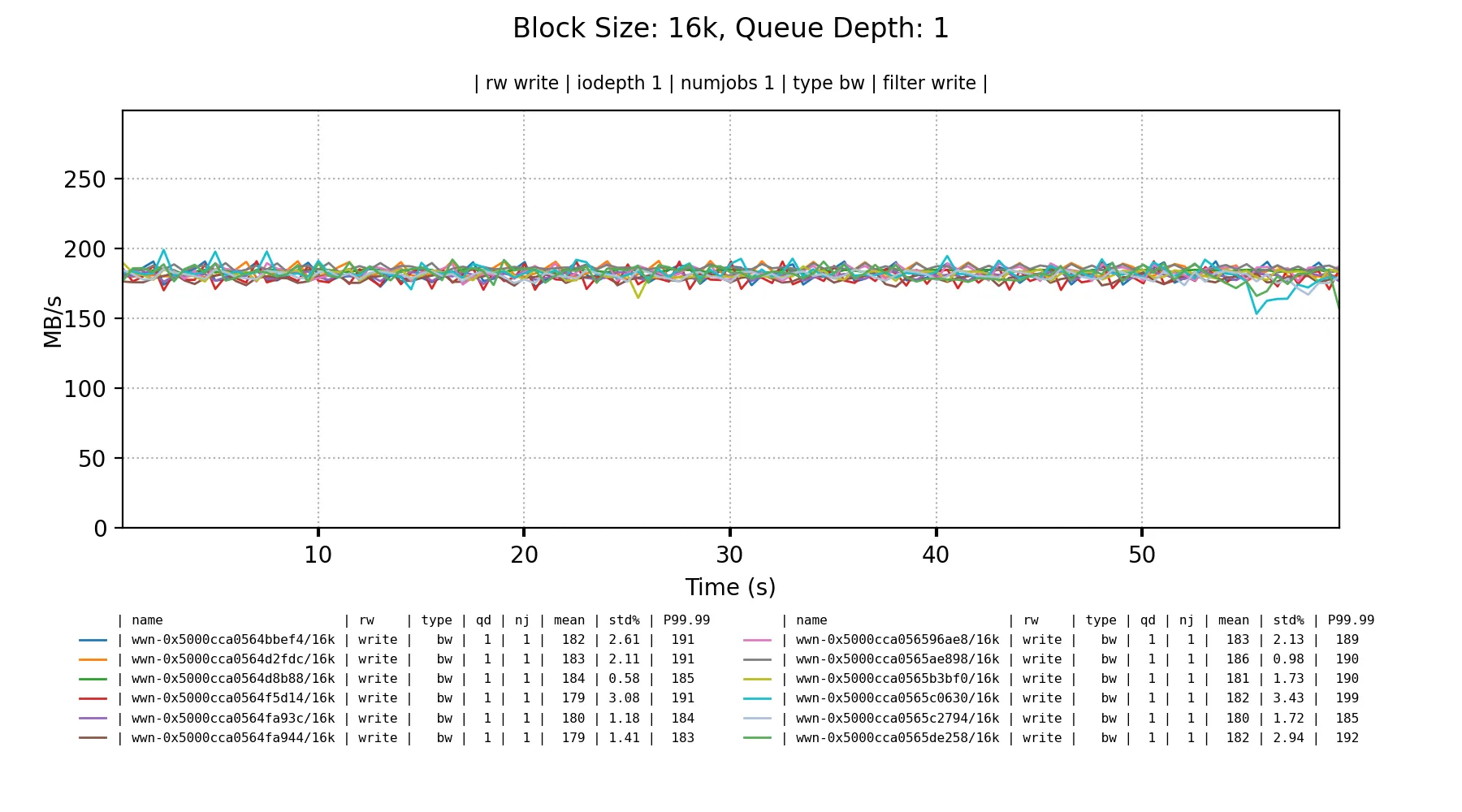
In the best case they get 180-190 MB/s bandwidth on sequential writes once either the queue depth is 4+ for 4KiB blocks, or single depth for 16KiB blocks.
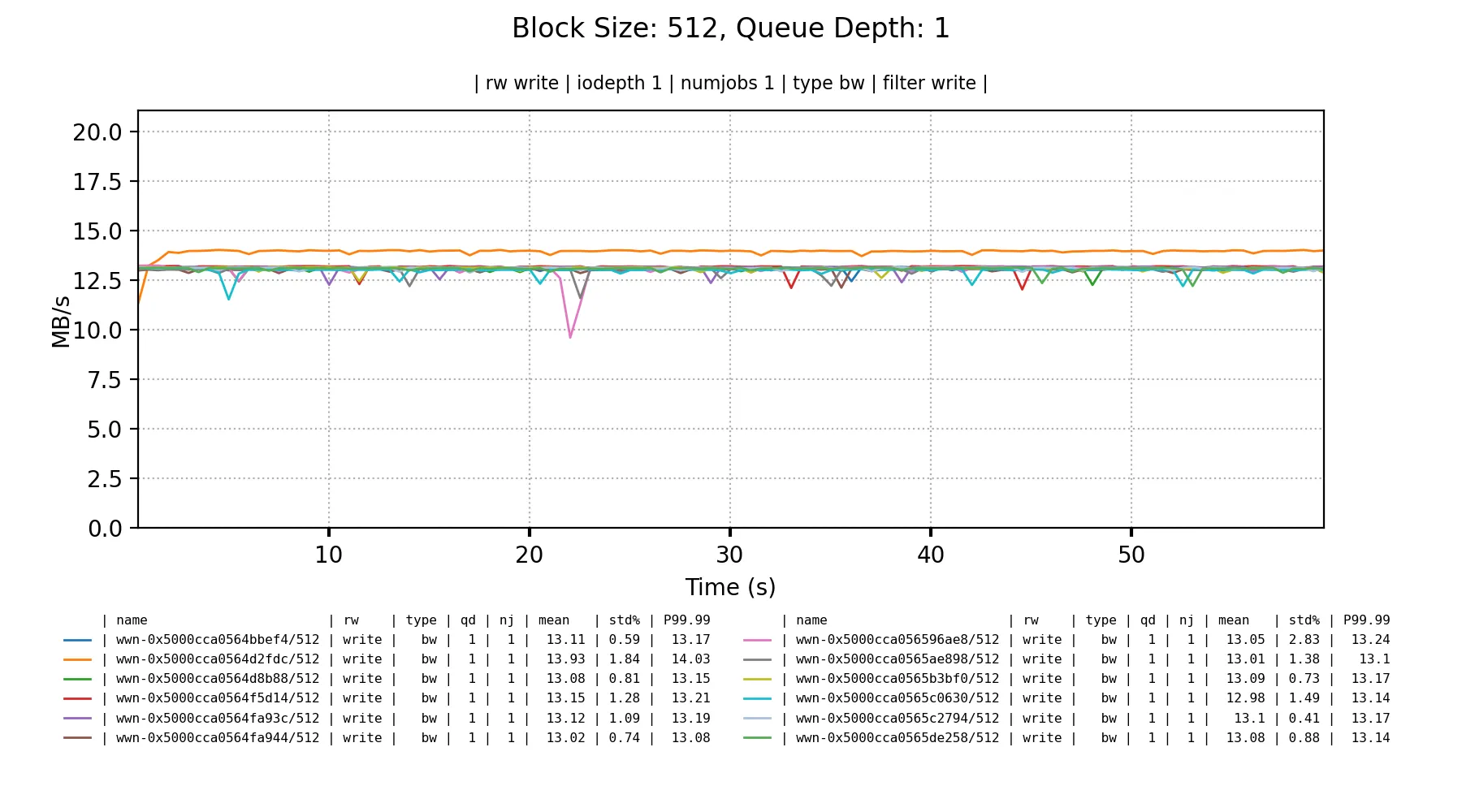
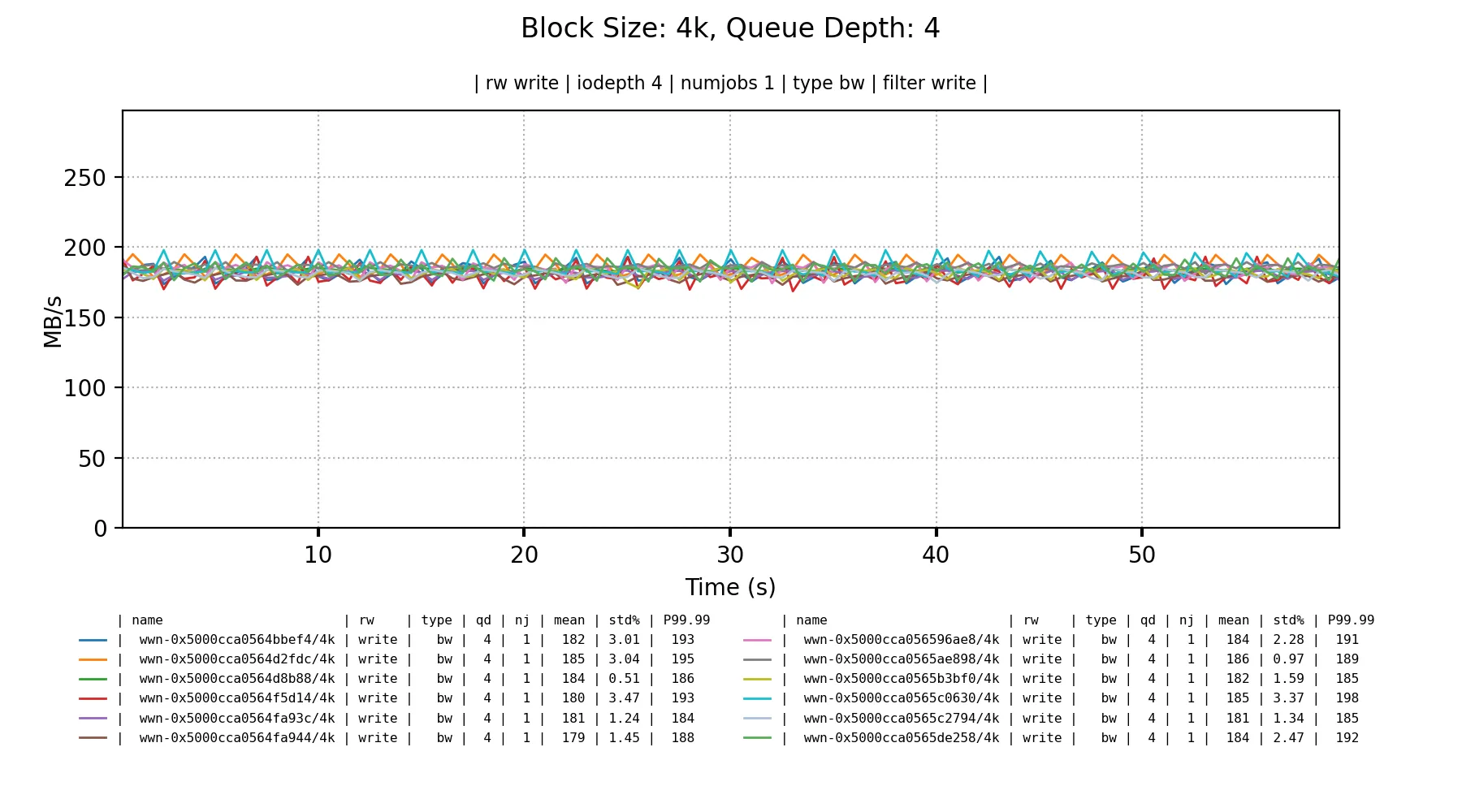
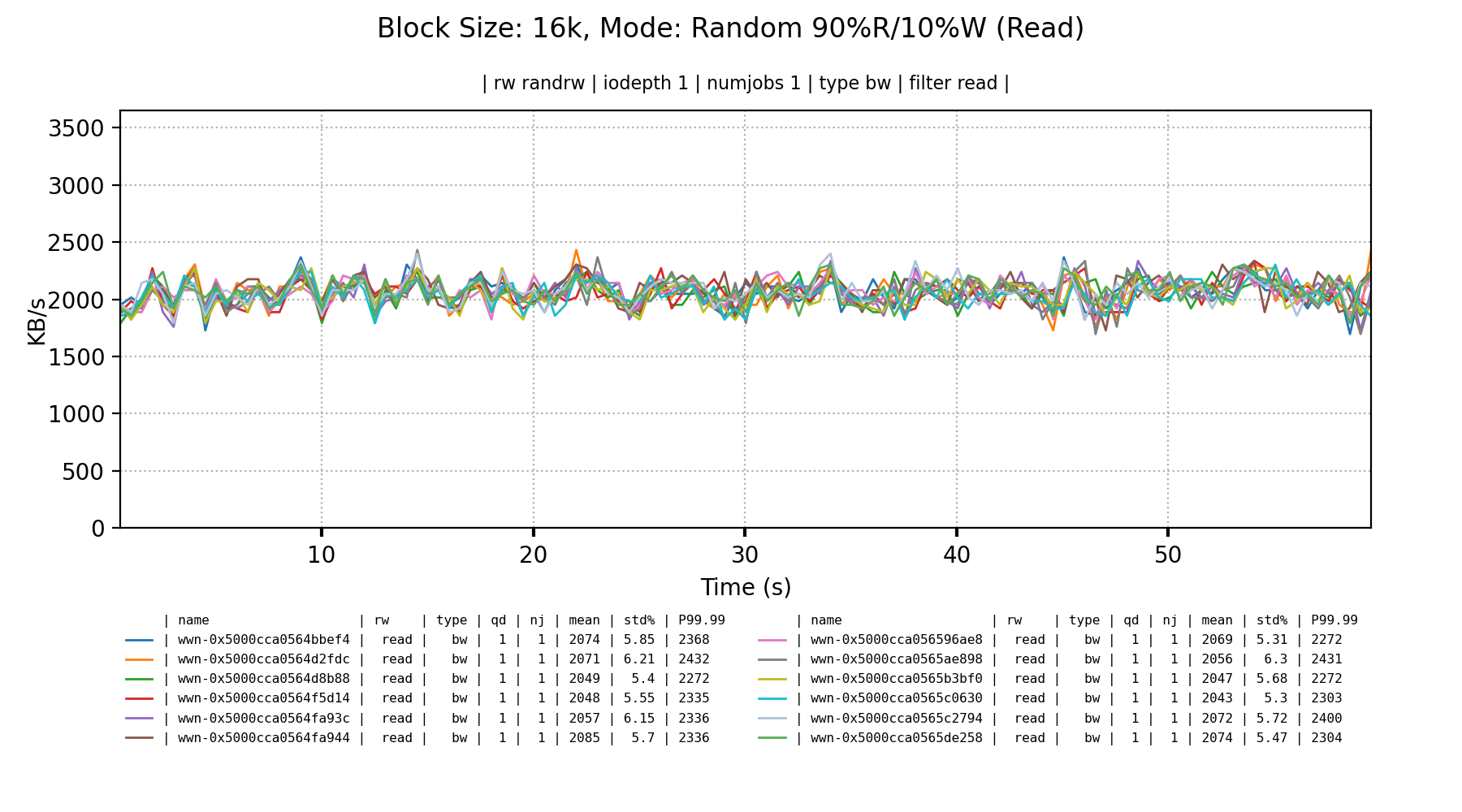
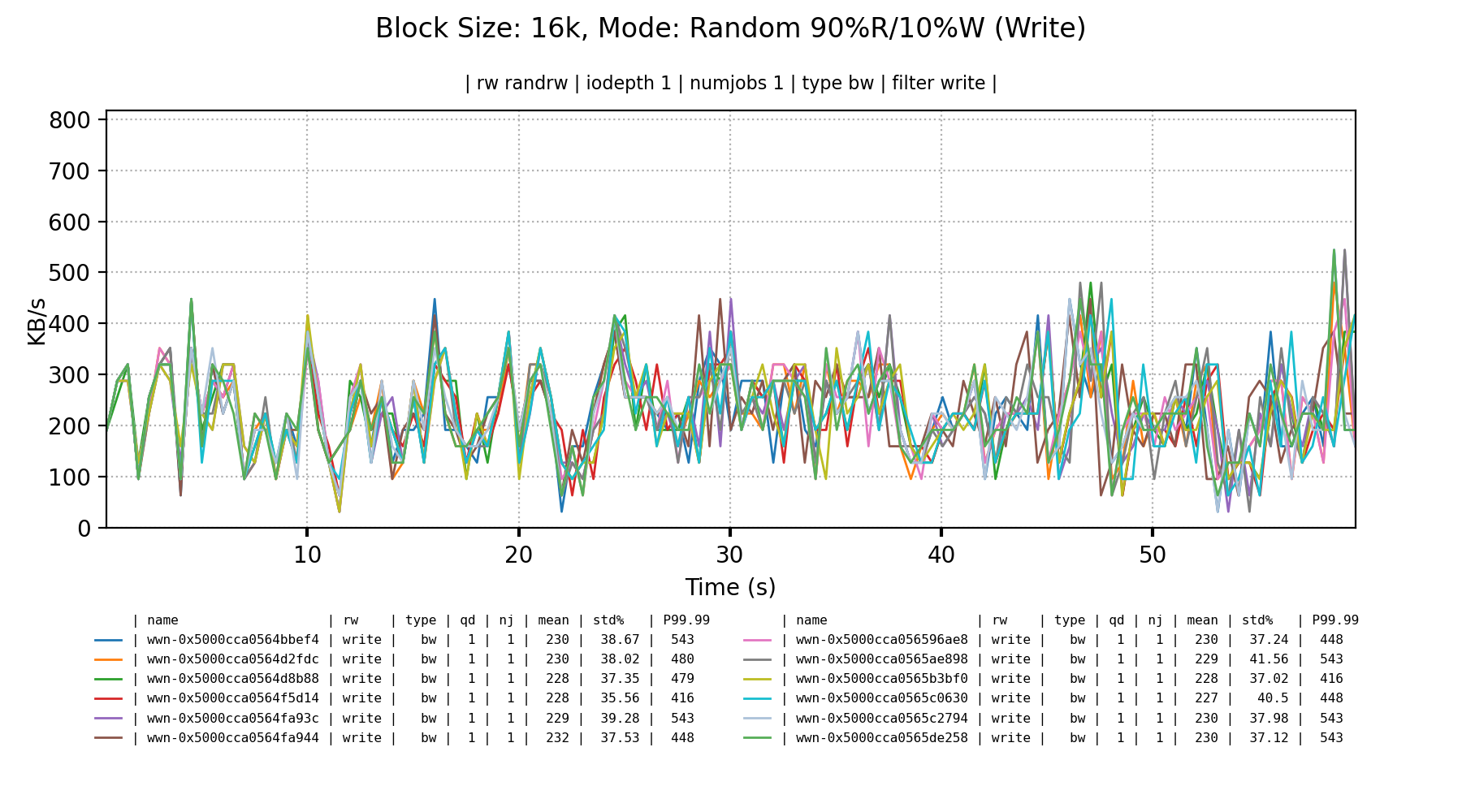
A mixed random read/write workload are about what I’d expect from these drives; invisible bandwidth with really small blocks.
Configuration
shell.nix
let
pkgs = import <nixpkgs> {};
optimizeWithFlags = pkg: flags:
pkgs.lib.overrideDerivation pkg (old:
let
newflags = pkgs.lib.foldl' (acc: x: "${acc} ${x}") "" flags;
oldflags = if (pkgs.lib.hasAttr "NIX_CFLAGS_COMPILE" old)
then "${old.NIX_CFLAGS_COMPILE}"
else "";
in
{
CFLAGS = "${newflags}";
NIX_CFLAGS_COMPILE = "${oldflags} ${newflags}";
});
optimizeForThisHost = pkg:
optimizeWithFlags pkg [ "-O3" "-march=native" "-mtune=native" "-fPIC" ];
# nativePkgs doesn't explicitly add the march/mtune=native flags
nativePkgs = import <nixpkgs> {
crossOverlays = [
(self: super: {
stdenv = super.stdenvAdapters.impureUseNativeOptimizations super.stdenv;
})
];
};
in pkgs.mkShell {
buildInputs = [
pkgs.python3
(optimizeForThisHost pkgs.fio)
(optimizeForThisHost pkgs.openssl)
nativePkgs.pv
# fio dep
pkgs.bc
] ++ (with pkgs.python3.pkgs; [
numpy
matplotlib
pillow
setuptools
]);
# shellHook = ''
# # Tells pip to put packages into $PIP_PREFIX instead of the usual locations.
# # See https://pip.pypa.io/en/stable/user_guide/#environment-variables.
# export PIP_PREFIX=$(pwd)/_build/pip_packages
# export PYTHONPATH="$PIP_PREFIX/${pkgs.python3.sitePackages}:$PYTHONPATH"
# export PATH="$PIP_PREFIX/bin:$PATH"
# unset SOURCE_DATE_EPOCH
# '';
}ZFS Pool creation
# 16k Block Size
zpool create \
-O aclinherit=passthrough \
-O acltype=posixacl \
-o ashift=14 \
-O atime=off \
-O compression=lz4 \
-O dnodesize=auto \
-O normalization=formD \
-O xattr=sa \
tpool \